Tags
In this post I’d like to tell you about some features of my currently preferred Tezos wallet – Kukai. I’ll tell you why I like it, and I’ll show you how to use Kukai’s unique Offline Signing feature.
Why Kukai?
Let’s start with why you might want to use this wallet. I like it for the following reasons:
Works Everywhere
Kukai provides native clients for Linux, Mac and Windows, and a web client that can be conveniently accessed from your browser from anywhere with an Internet connection.
Private Keys Never Leave Your Device
The private keys are stored in a local file on your computer (or in your browser’s local storage while you use the web client), but your keys are NEVER sent over the Internet. The local wallet file containing all the sensitive data is made easily accessible to you, so that you decide how you wish to manage the security of your private key. Furthermore, the sensitive data inside this file is encrypted with a password that hopefully exists only in your head.
Offline Signing
This is the most interesting and so far, unique feature in Kukai. Offline Signing is a really simple, but powerful idea that provides the highest level of security. If you set this up correctly, the security can be as good as a hardware wallet. The usage of this feature is optional, but very interesting and will be the focus of this guide.
Why Offline Signing?
It might be helpful to talk about why Offline Signing is something you might consider using.
The idea is simple – any Internet-connected computer is at risk of being hacked. Period. Even if your computer was perfectly secured, the user never can be ;).
So even though your private keys are never sent over the Internet by the wallet on purpose, attackers can still get them from you with any number of techniques. Here are just a couple of most common examples:
- Link manipulation: The attacker might fool you into clicking on a malicious wallet link that is slightly different from the real link. It will take you to the attacker’s website, which will look exactly like your wallet. If you don’t notice this in time, you’ll end up typing your passwords and providing your wallet file to the attacker.
- Virus: Your computer might be infected with a key logger virus, or a browser extension that records everything you type and steals specific files from your computer. Attackers will eventually get both, your wallet file and your password.
The ONLY sure way to be safe is to never store or access your private keys on an Internet-connected computer at all.
This is exactly where Kukai’s Offline Signing feature comes in. The idea is to use one computer to create and send transactions to the Tezos blockchain, and another separate, disconnected computer to sign these transactions with your private key.
Setting up this system is very easy, as long as you have another device to dedicate to this process.
Setup
Offline Signing will require 2 computers/devices – one connected to the Internet and one offline device, used exclusively for signing Tezos transactions. I’ll designate operations on the Internet-connected machine (aka “Workstation“), with green text, and operations on the signing machine (aka “Signer“), with red text.
It is completely up to you what kind of devices and operating systems you want to use on the Workstation and Signer. My personal preference for the Signer’s OS is Lubuntu (https://lubuntu.net/), because it is very quick and easy to install and configure.
If you do end up using a Linux distro on the Signer, please make sure you have this package installed while still connected to the Internet during your install:
$ apt-get install libgconf2-4
This library is required to run Kukai’s native Linux client.
After you are done performing the initial OS install on the Signer, and possibly installing the latest updates from the Internet, disconnect Signer from the Internet. The Signer is now purely an offline machine.
Installing Kukai on Signer Machine
On the Workstation
- Download Kukai stand-alone client from https://github.com/kukai-wallet/kukai/releases. Select the build that matches your OS.
- Verify the checksum. This is how you ensure that nobody is messing with you and that the wallet has not been modified in any way en-route to your computer.
$ sha256sum kukai_linux_x64_1.0.3.tar.gz 012cf59820c84a7bd4f61414d02ad8196e8f4e317fa7905e81d59efc82da6901 kukai_linux_x64_1.0.3.tar.gz
- Compare that number to the number on the download page. It must match exactly!
- Copy kukai_linux_x64_1.0.3.tar.gz to a USB stick and place it somewhere on your Signer machine.
On Signer
- Extract:
$ tar zxvf kukai_linux_x64_1.0.3.tar.gz
- And run:
$ cd kukai_linux_x64_1.0.3/ $ ./kukai
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
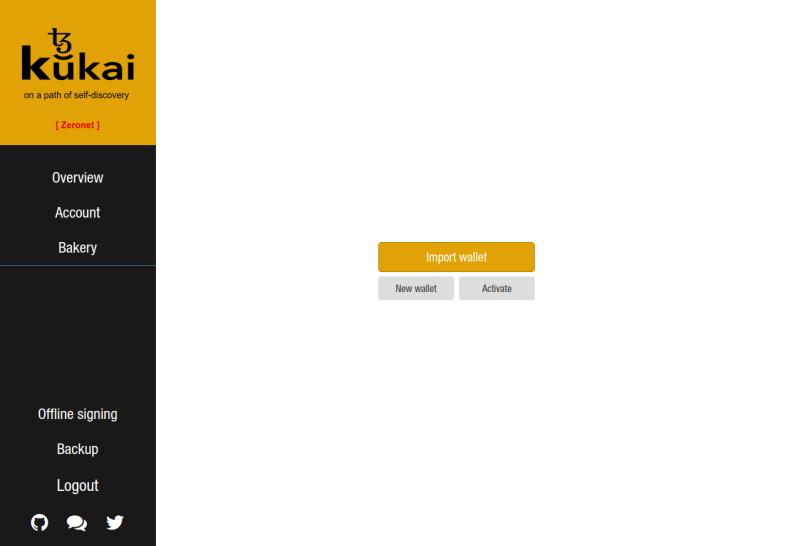
Creating or Importing a Wallet
When Kukai starts, you’ll be presented with different options to get your wallet started. In this guide I’ll assume that you’ll be importing a wallet that was created during the Tezos ICO, but other scenarios will be very similar.
- If you have not yet activated your Tezos ICO account, do so now by selecting Activate and providing your ‘public key hash’ and your ‘activation code’ (obtained from here: https://verification.tezos.com/).
On Signer
- Once activated, go to Import wallet -> Retrieve wallet and provide the full wallet information. After you do that correctly, Kukai will ask you to provide an additional password to encrypt your Kukai wallet, which contains your private key (among other things). This means that if someone gets a hold of your Kukai wallet file, it is still useless to them without this password. Please make sure that this password exists only in your head.
Feel free to make this password as long as you need, because humans are very bad at remembering short cryptic passwords like ‘s7ya48u1EE’, and computers are very good at cracking them. Instead, try something like ‘correct;horse;battery’ or ‘enlightened:papal:shrimp’. You’ll never forget it and its super-hard to brute-force or guess a password like that.
You’ll be presented with an Overview screen for your wallet:
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>

>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
Exporting Your Wallet
On Signer
The next thing to do is to export 2 versions of the wallet you just created. Go to the Backup menu in Kukai and export:
- The Full Wallet. This file will be called something like ‘wallet.tez’, and will contain your public and private keys. Feel free to rename it to something better. This wallet file can be used to gain full access to your tezzies, so be careful with it! Save this file somewhere on the Signer machine and maybe even back it up somewhere else for safety. But don’t stress too much – the private key in this file is encrypted with the password you selected earlier, so the file by itself is still useless without it.
- The View-only wallet. You’ll need to enter your wallet password and click on the Generate button. This file allows you to see your tezzies, but not actually access them, because your private key is not in this file. If someone gets a hold of it somehow, all they get is the ability to see how many tezzies you have, and what you have done with them in the past. This is the file we’ll use on the Internet-connected machine (Workstation).
Take the ‘view-only_wallet.tez’, put it on a USB stick and take it to your Workstation machine.
Import View-only wallet
Now that we have our view-only wallet, we can safely use it in Kukai web-client on the connected Workstation. It is convenient, and we no longer have to worry about getting hacked, since our private key is not stored anywhere on the connected Workstation.
On The Workstation:
– Go to https://kukai.app/
– Import Wallet -> Import wallet from File and select your ‘view-only_wallet.tez’ file we brought over from the Signer machine.
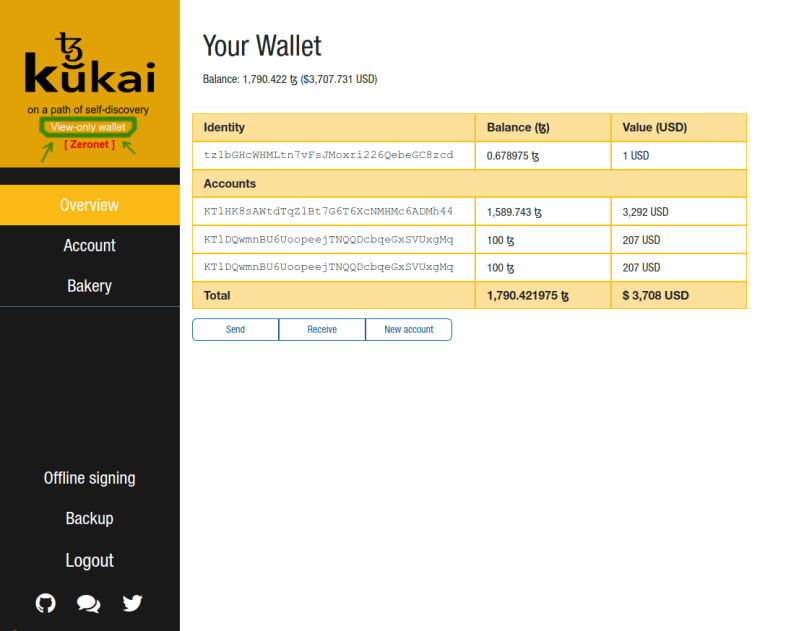
Note that the Overview screen contains all of the account info that we saw on the disconnected Signer machine, and all of the operations like Send, Receive and New Account are still available, but the wallet is marked as “View-only”:
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
And that’s it! Your setup is now complete.
Slinging Tezzies
Ok, let’s move some tezzies around. In this example I’ll move 500 XTZ between my own accounts. Let’s say from tz1bGHcWHMLtn7vFsJMoxri226QebeGC8zcd to KT1DQwmnBU6UoopeejTNQQDcbqeGxSVUxgMq. See the picture above for reference.
On The Workstation
- Go to Overview -> Send
- From: tz1bGHcWHMLtn7vFsJMoxri226QebeGC8zcd []
- To Address: KT1DQwmnBU6UoopeejTNQQDcbqeGxSVUxgMq
- Amount: 500
- Click Preview -> Confirm
- You should get a message that says: “Your unsigned transaction has been created successfully“
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>

>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
- Download it. Let’s give it a name like ‘demo1.tzop’
- Put ‘demo1.tzop’ on a USB stick and take it to the Signer machine.
On The Signer
- Run the native Kukai client (if not already running):
$ cd kukai_linux_x64_1.0.3/ $ ./kukai
- Your Full Wallet should already be loaded here, but if not, just go to Import wallet -> Choose File again and select the full wallet file you saved earlier.
- Go to Offline Signing -> Sign operation (offline) -> Choose File, and select the unsigned operation file (‘demo1.tzop’).
- Verify that what you are about to sign with your private key is correct and awesome:
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>

>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
- Type in your wallet password in the Password field and click Sign…………..
- If all went well, you’ll see a success message saying: ‘Operation successfully signed!‘
- Download the signed operation file. Call it something like: ‘demo1_signed.tzop’.
- Put it on the USB stick and take it to the Workstation.
On the Workstation
- In Kukai, go to Offline signing -> Broadcast -> Choose file and select ‘demo1_signed.tzop’ from the USB stick.
- You can see what you are about to broadcast by clicking Yes on “Would you like to decode the operation?”
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>

>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
- Click Broadcast. You’ll be provided with the Operation Hash for your transaction.
And you are done!
You can go to the Account menu to see the transaction. Or you can use the Block Explorer to look at it:
https://tzscan.io/<Operation Hash>
Final Word
This is clearly a somewhat lengthy process, but some amount of inconvenience is always the trade-off for extra security.
If you do lots of small operations in a day, you could optimize this workflow by creating another Full Wallet on the connected Workstation, with a small amount of tezzies in it – for convenient day-to-day tasks, and keep the majority of your Tezzies in the offline Signer wallet for any large transfers. That way if your Workstation does get compromised, you only lose a small amount of tezzies instead of everything.
I hope this guide was helpful to someone.